

How Green is your Equity Index? Giving an ESG Score to any Equity Index using Python!



ESG, The most widely used acronym today in the Financial Services industry. I don't know if you have noticed, but ESG funds have been popping up out of nowhere globally, and investment banks are suddenly competing against time to launch ESG tilted funds. Small retails firms whose all focus is ESG have been getting tons of clients.
Not only are asset managers or investment banks milking this acronym to the last drop, even data companies and data science platforms like Dataiku, DataBricks are taking full advantage of this surge in demand and selling their expensive platforms to Big Banks.
Not to forget the Data Companies like Bloomberg, Sustainalytics have come up with unique premium alternative data products to sell like a $24000/Yr Bloomberg Terminal cost was not enough already. Still, well banks are willing to pay for it.
But Why? What is the Hype?
Well, for starters, ESG (Environment, Social & Governance) score is a measure of the environmental and social goodness of the company, the logic behind ESG being if companies try to improve their overall social image and be nice to the Earth also while keeping good governance practices in place, not only will it become more profitable and valuable over time but will also advance society's best interest while also making investor's money. Does it not sound like a win-win to you?
Well, it will be interesting to see if, in the long term, these ESG funds outperform the traditional funds or not. Still, for now, ESG investing is at the heart of every asset manager; for example, BlackRock, the world's largest asset manager, sells 5.7% (142 out of 2503) of their total retail funds as ESG Funds. Fund Details available here.
So, as a retail investor, if you want to get into ESG investing and take advantage of this surge in interest to your benefit, how do you cost-effectively do that? We can't afford to spend $24000/Yr on Bloomberg and even pay a premium for ESG products.
Well, you are in luck; today, I will show you a clean method via Python to access the Environmental, Social, and Governance Score for each company. We will be doing this exercise for all the companies in FTSE 100 and NIFTY 50 and then cleaning the data to give an overall weighted average ESG score to the index, which will help you determine how GREEN each index is, no - not the money green, I meant the ESG green. Only time will tell if the money will also turn green.
Methodology
- Yahoo Finance publishes Sustainability data on 1000+ companies, and the data provider for this is Sustainalytics, as noted on their website.
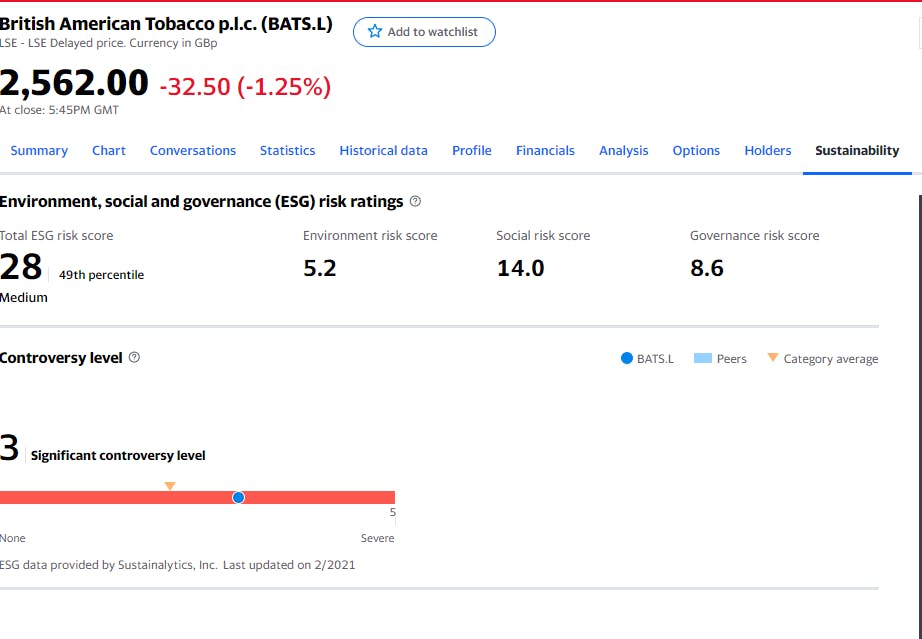
We will collect this data for all the constituents of both indexes.
For some companies where the ESG scores are not available, we will assign them the industry averages for fair representation as both the indexes will have more than one company in the same sector.
If all companies in a particular sector do not have ESG scores, we will take the average ESG scores of the whole index and assign them to such companies to smoothen the data; FYI: there will be no such cases the indexes we are dealing with for this article.
We will also collect the Last Traded Price and Shares Outstanding of all the companies to calculate its market value and its weightage in the respective index.
Finally, we will multiply the weights of the companies in the index (since they are market-cap weighted index) with their ESG score to arrive at weightedESGScore. Finally, we will sum all the weighted scores to arrive at an overall score for the index.

Before I get into the Python Implementation of this ESG score, I will publish the results for readers interested in the final results. 🏆
Results (Lower Score is Better)
| Score | NIFTY50 | FTSE100 |
| environmentScore | 7.0 | 6.58 |
| socialScore | 10.6 | 9.95 |
| governanceScore | 9.58 | 7.2 |
| totalEsgScore | 27.18 | 23.73 |
The lower the score, the more ESG efficient the index is 🌎
Notes to this Analysis:
The individual company index weight will not precisely match our method due to limitations of data scraped, and direct data is costly to obtain.
All figures as of 17th Feb 2021
Around 20 companies in FTSE100 and 7 companies in NIFTY50 did not have ESG data and have been normalized with the methodology stated above.
Python Implementation
First things first, obtaining meaningful data in the correct format direct is every data analyst's dream but is only often a reality. We will be working on a lot of cleaning and scrubbing on this implementation.
Python Library Used:
time
random
Step 1: Install The Libraries and Import Themconda install pandas or pip install pandasconda install -c ranaroussi yfinance or pip install yfinance
import pandas as pd
import yfinance as yf
import time
from random import randint
If you are just getting started with Python and don't know what the above means, I would recommend you to check this article.
Step 2: Loading the Tickers
Readers can download the list of FTSE100 tickers from here, and the NIFTY50 tickers can be downloaded from here, ensure to download in .csv format. The tickers have been downloaded from LSE and NSE's website and is publicly available.
The below implementation uses NIFTY50 as an example, if you would like to see the same for FTSE100, you can open this Google Colab Notebook.
df = pd.read_csv('/path/to/file.csv') #give the full path of file downloaded
index_tickers = df['Symbol'].tolist() #assigning all tickers to a list
print(index_tickers)
It is just printing the list of tickers to do a sanity check that everything looks good. This is what it would look like for the NIFTY50 index.
Step 3: Downloading ESG Data from Yahoo Finance
Let's first see what the sustainability attribute of yfinance library returns.
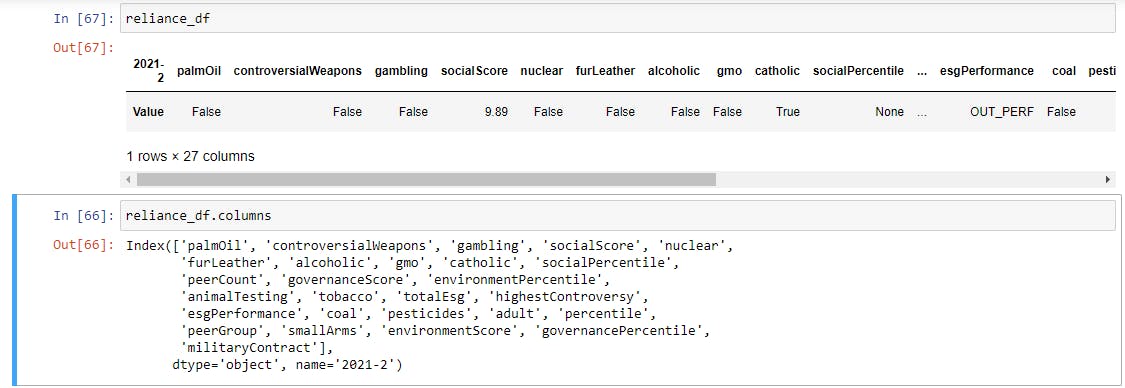
reliance = yf.Ticker("RELIANCE.NS") #creating a new object for RELIANCE stock
reliance_df = reliance.sustainability.T #getting ESG data from Yahoo in a dataframe format
# pandas function .T is used to transpose the dataframe
The table returned by the above code has 27 columns and will look like below, along with the following column names. This table has a lot more information and most of which will not be required by us.
Now that we know, how the response data frame is like, let's create a loop to go over all the tickers in the index and create one single table.
esg_data = pd.DataFrame() #empty df for attaching all ticker's data response
for ticker in index_tickers:
print(ticker) #just FYI to know your code is running
ticker_name = yf.Ticker(ticker)
try:
if ticker_name.sustainability is not None: #if no response from Yahoo received, it will pass to next ticker
ticker_df = ticker_name.sustainability.T #response dataframe
ticker_df['symbol'] = ticker #adding new column 'symbol' in response df
esg_data = esg_data.append(ticker_df) #attaching the response df to esg_data
time.sleep(randint(2,8)) #delaying the fetch of data for 2-8 seconds
except (IndexError, ValueError) as e: #in case yfinance API misbehaves
print(f'{ticker} did not run') #FYI
pass
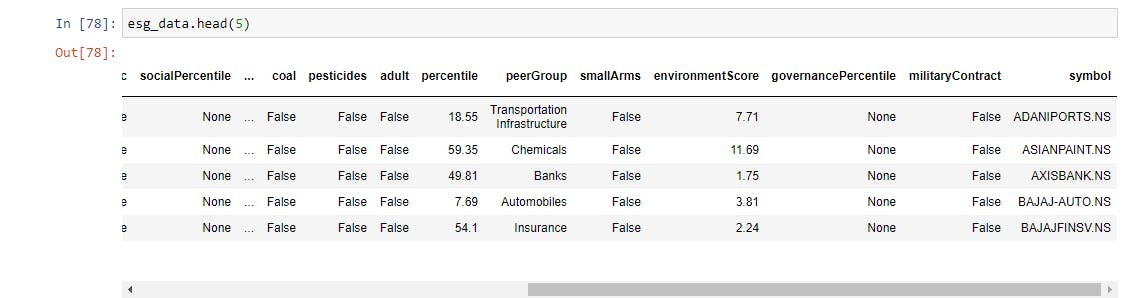
In the above code, you will notice a random delay in the next run for 2-8 seconds; this is to avoid sending too many requests to Yahoo Finance too frequently, blocking our IP address for some time. Let's see what the first five lines of our final ESG data frame look like.
esg_data.head(5) #calling first 5 rows
Step 4: Finding out which tickers did not return ESG data and Filtering ESG DataFrame for Essential Columns only
It is crucial to analyze the gaps in data and fix them by filling with correct information to do meaningful analysis. Let's quickly check which securities did not have ESG data.
esg_tickers = esg_data['symbol']
no_esg_data = list(set(index_tickers) - set(esg_tickers))
#set function removes all duplicates in a list and the above gives us the
#difference between our original ticker list and our esg_data ticker list
print(no_esg_data)
The below stocks do not have any ESG data on Yahoo Finance; go ahead and check manually as well. We will deal with them in Step 7

Now, let's also strip our 27 columns into just 5 columns, which we need.
new_esg_df = esg_data[['symbol', 'socialScore',
'governanceScore', 'totalEsg', 'environmentScore']]
#the above basically takes the columns mentioned above and assigns into new df.
new_esg_df.head(5) #let's see what it looks like
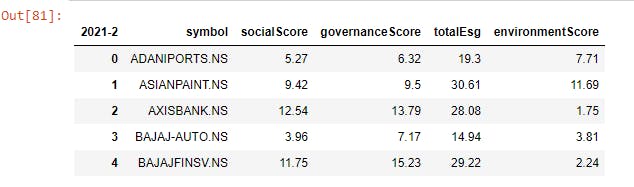
Step 5: Downloading Last Price, Shares Outstanding Data from Yahoo Finance
The .info attribute of the yfinance returns a whole lot of comprehensive information, and like the ESG data, we wouldn't need most of it; we are mostly interested in four data points which are ['symbol', 'sector', 'previousClose', 'sharesOutstanding']
Don't worry; I have made the code easy to understand, but first, let's see how the original response looks.
print(reliance.info) #using same reliance object created before

The response object is of the data type dict. Now, let's prepare a loop to get this data for all members of the index and convert these dicts into a data frame
main_df = pd.DataFrame() #creating empty df to store data
for ticker in index_tickers:
ticker_name = yf.Ticker(ticker)
try:
ticker_info = ticker_name.info
ticker_df = pd.DataFrame.from_dict(ticker_info.items()).T
#the above line will parse the dict response into a DataFrame
ticker_df.columns = ticker_df.iloc[0]
#above line will rename all columns to first row of dataframe
#as all the headers come up in the 1st row, next line will drop the 1st line
ticker_df = ticker_df.drop(ticker_df.index[0])
main_df = main_df.append(ticker_df)
time.sleep(randint(2,8))
print(f'{ticker} + Complete')
except (IndexError, ValueError) as e:
print(f'{ticker} + Data Not Found')
Since our main_df has a lot of information we don't need, let's filter this dataframe to only the essential columns we need.
filtered_df = main_df[['symbol', 'sector', 'previousClose', 'sharesOutstanding']]
filtered_df.head(5) #checking how first 5 rows look like
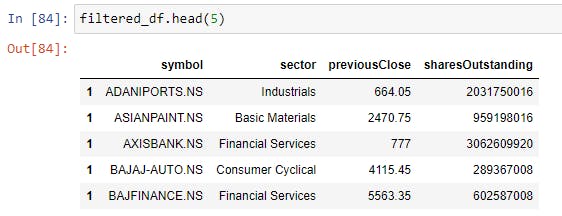
Insert Image here
Step 6: Calculating Company Index Weight and Merging ESG table and Info Table
We have now got the data required to calculate our company weight in the index, but first, we need to calculate the market value of each company by using newMarketValue = (previousClose * sharesOutstanding)
The Total Market Value of the index will be sum(newMarketValue)
Let's add these two new columns to our filtered_df
filtered_df['newMarketCap'] = filtered_df['previousClose'] * filtered_df['sharesOutstanding']
total_index_mcap = filtered_df['newMarketCap'].sum()
filtered_df['marketWeight'] = ((filtered_df['newMarketCap']/total_index_mcap)*100
This is how the first five lines of the table would look like...
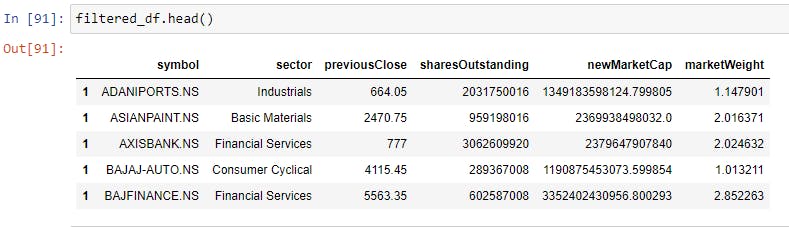
Now, time to merge the two tables we have been working on to complete our analysis. Let's call this table final_df
final_df = filtered_df.merge(new_esg_df, how='left', on='symbol')
#for more info on .merge visit https://bit.ly/3pFlYIm
This is how the first five lines of the table would look like...
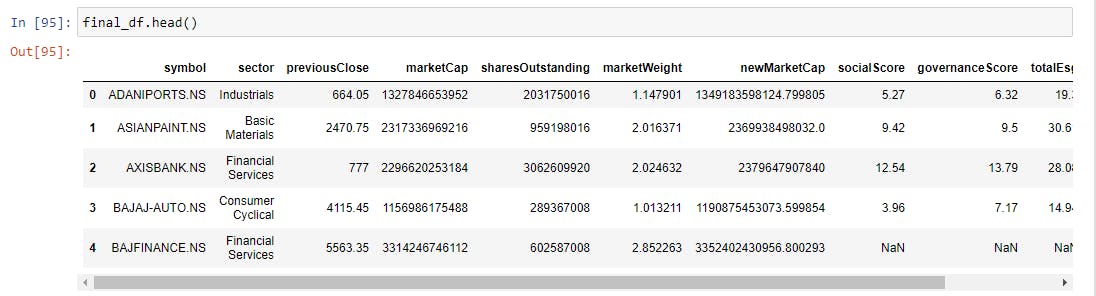
IMPORTANT: Remember in Step 4 we discovered that 7 tickers did not return any ESG data, but we do have all other information about them; in the next step, I will show how we can assign these tickers the average ESG scores of their industry.
If you want to quickly check what these stocks are and what sector these are from, the below code will help.
final_df[~final_df['totalEsg'].notnull()]
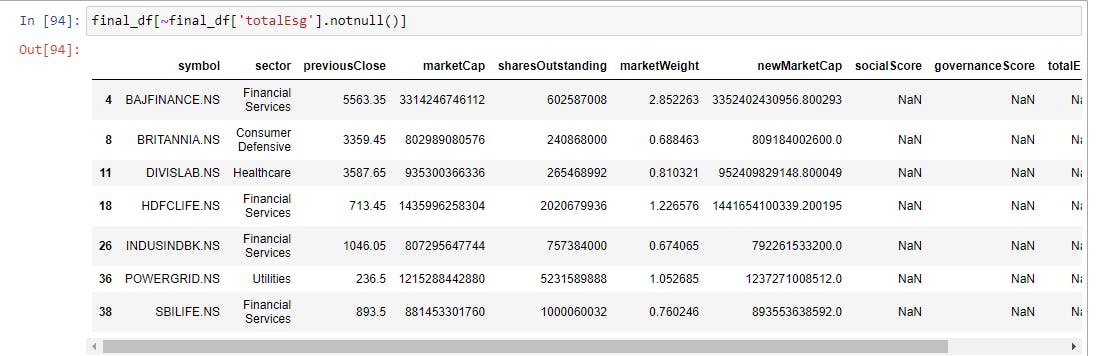
Step 7: Filling all NaN ESG values with their Industry Averages
First, we will filter the data frame sector-wise and then apply .fillna to fill their industry average for each score and let's store all this data in a new empty data frame.
final_esg_df = pd.DataFrame() #empty df
sector_list = final_df['sector'].unique().tolist() #getting list of sectors in index
#looping over each sector and apply .mean to calculate average
for sector in sector_list:
sector_df = final_df[final_df['sector'] == sector]
sector_df['socialScore'].fillna(round(sector_df['socialScore'].mean(),2), inplace=True)
sector_df['governanceScore'].fillna(round(sector_df['governanceScore'].mean(),2), inplace=True)
sector_df['totalEsg'].fillna(round(sector_df['totalEsg'].mean(),2), inplace=True)
sector_df['environmentScore'].fillna(round(sector_df['environmentScore'].mean(),2), inplace=True)
final_esg_df = final_esg_df.append(sector_df)
#also adding the weighted average columns into this new final_esg_df
final_esg_df['mktweightedEsg'] = (final_esg_df['marketWeight'] * final_esg_df['totalEsg'])/100
final_esg_df['mktweightedEnvScore'] = (final_esg_df['marketWeight'] * final_esg_df['environmentScore'])/100
final_esg_df['mktweightedSocScore'] = (final_esg_df['marketWeight'] * final_esg_df['socialScore'])/100
final_esg_df['mktweightedGovScore'] = (final_esg_df['marketWeight'] * final_esg_df['governanceScore'])/100
We are almost there; your data-analysis is complete, all you need to do right now is take the sum of columns ['mktweightedEsg', 'mktweightedEnvScore', 'mktweightedSocScore', 'mktweightedGovScore']
print('Total Environment Score: {}'.format(round(final_esg_df['mktweightedEnvScore'].sum(),2)))
print('Total Social Score: {}'.format(round(final_esg_df['mktweightedSocScore'].sum(),2)))
print('Total Governance Score: {}'.format(round(final_esg_df['mktweightedGovScore'].sum(),2)))
print('Total ESG Score: {}'.format(round(final_esg_df['mktweightedEsg'].sum(),2)))

Congrats!! 🍾 You Did It!
I hope you had a good read and learned a couple of things on how the whole process works like and I can't wait to see what you build with these ideas! I would recommend you to copy paste the whole code and do a similar thing with FTSE100.
You can also access Github here to directly view the whole code in one single file.
And that's a wrap! I hope you enjoyed this article. If you have any questions, please feel free to leave a comment and consider subscribing to my mailing list for automatic updates on future articles. 📬
If you liked this article, consider buying me a coffee ☕ by clicking here or the button below.