




Welcome Readers 🤩 to the fourth article in the series "NSE EOD Stock Prices." This article will discuss how to use Python to download Corporate Action Data from the Bombay Stock Exchange.
If you haven't checked out the previous articles in this series, you can click here to read all the articles in one place.
Before we start implementing scraping BSE to get this data daily, I want to share my pain 😞 with you on how difficult it was to devise a good-enough (not perfect) methodology to collect accurate data. When I started this series, I was confident that I have all pieces of information I will need to complete this project, but oh god, how wrong I was; while the corporate action data is available within various APIs and websites, none of them are perfect with everyone having their limitations. I am sharing the list which I researched and their limitations. You can click on the names below; they are hyperlinked to relevant sources.
FMPCloud API: Perfect simple to use API gateways to get data in JSON format, but the data is not reliable for Indian Markets contacted the support team with those discrepancies, and they confirmed they would be working on rectifying the inaccuracies I have highlighted. Still, for now, they are a no-go.
yfinance by Ran Aroussi: Probably the most starred API out there to get historical data and widely used, the problem was not with the API but with Yahoo Finance, they even adjust the actual dividend numbers for corporate action adjustments which can be very confusing to deal with, I even came around instances of missing data.
Investpy by Alvaro Bartt: Problems with how the API is implemented, the universal stock database is not updated frequently, and you will miss all the tickers which are not in the master file. So the information is at Investing.com, but the API doesn't return everything and, in most cases, will give you an error saying ticker not found. You can read more about the issue here.
Trendlyne: Very reliable data but no official way to get the data for free and scraping their data would require a lot of time cleaning it, also, no stock ticker/symbol available in data which kind of get's impossible to do the accurate mapping.
NSE Website: Another nightmare, official data but not structured, the"Purpose" field is free text, so it gets difficult to apply a methodology.
I wanted an open data reliable data-source for my readers to follow me, but because of my misery above, I tried exploring even moderately expensive data providers to get accurate data; I tried Zerodha, Fyers, but then soon realized that they are themselves plagued by the issue of adjusting their data. Read more about Zerodha API issues here. If you know of another free resource that can provide this data, please let me know, and I will be really grateful. 🤝
Our Python Implementation
At the start, I mentioned that we would be using BSE instead of NSE. Still, I will tell you that it wouldn't matter for 90% of equities which are listed on NSE, the rest 10% are just illiquid stocks where backtesting/technical analysis would anyway not work, so I am guessing we should be good because those 90% stocks which are listed on NSE are also on BSE so that we can handle this. Yes, there might be symbol variations between the two exchanges, but we will adjust for that. Also just wanted to mention that a corporate action on the company will be the same on both the exchanges for securities listed on both; there should be no difference.
The Plan
Scrape BSE for Dividends, Splits, Bonus Corporate Actions Data.
Clean the Data collected using
pandasUse the data to calculate dividend, split and bonus adjustment factors.
Adjust our main data for these corporate actions.
Of course, each topic would require its own article, just due to the complexity and the speed I want to explain this, so yes, that's the plan.
Libraries Required
time,glob,os- Default Python Librariesselenium- Install usingpip install seleniumorconda install seleniumundetected_chromdriver- Install usingpip install undetected_chromedriver
undetected_chromdriver is basically just like selenium but is maintained with the aim that modern websites are unable to track that you are running a code/algo to scrape their data; it also downloads the required webdriver to scrape this data if you don't have it on your machine, easy to use. You can read about it more here.
Showing our actual data source and its structure.
Click Here to go to BSE's website from where we will be downloading the data, the segment is by default Equity and the date is Ex-Date, don't worry about any of the other fields and move on to Purpose field where you can select the relevant corporate action. I will only be covering the extract of Dividends, Splits, and Bonuses because these actions affect the stock price. You can read an article from Zerodha on this here.
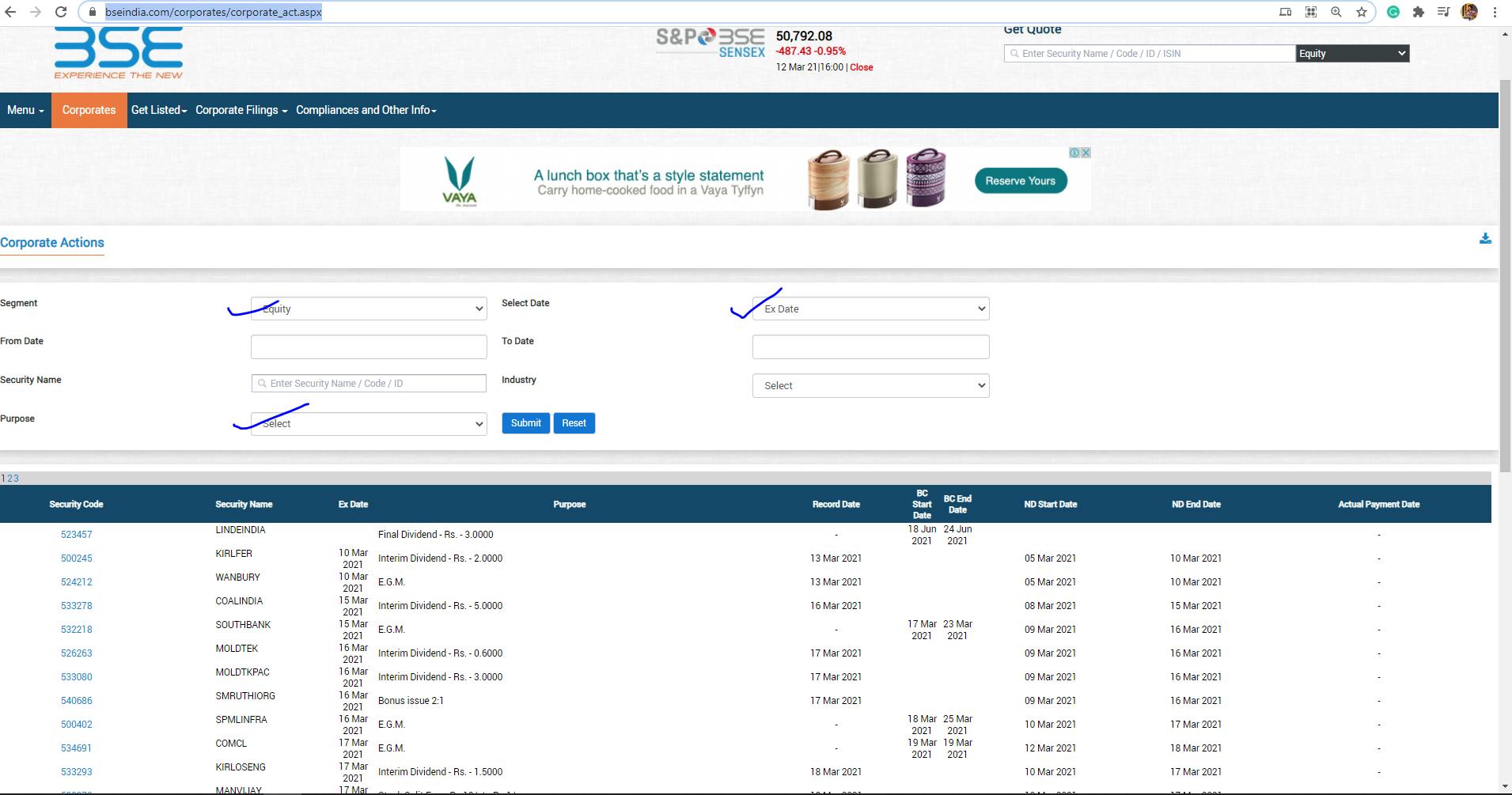
Just selecting Dividend in Purpose and Submit, you will see the list of all Dividends from 2000. You will notice a small excel icon at the end of the screen to download the .csv; that's what we need to do, download this data periodically to adjust our main data.
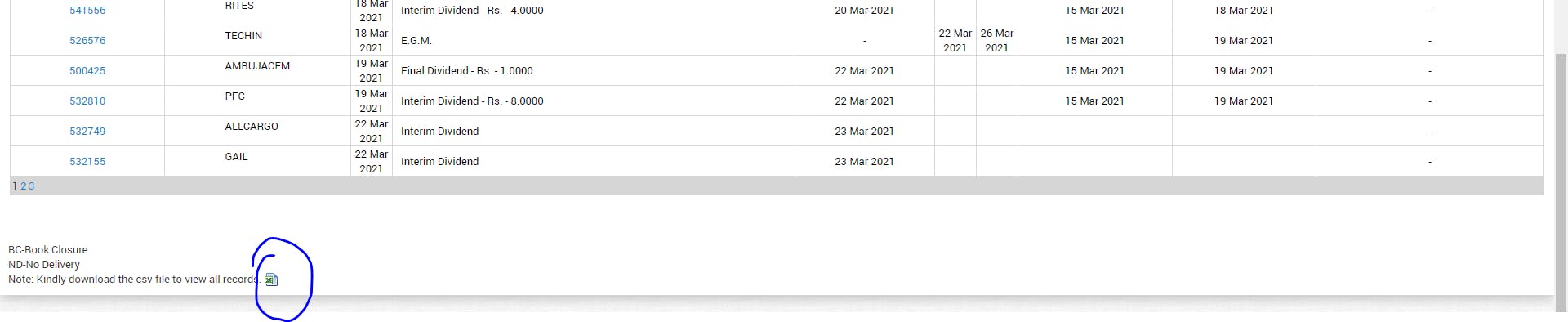
And why do I say this is a good-enough solution and not the best, because there will be occasions that you would still miss these corporate actions due to exchanges delaying updating symbols, due to incorrect/incomplete data at BSE, but that's a problem everyone faces, large firms especially have corporate actions teams to adjust all this data on a day-to-day basis (yes, I am not joking, I have seen it), so yes, no one solution fits all. Still, as long as you are dealing in liquid stocks, I don't expect any problems.
Code on Github
Unfortunately, the code to do this is too big, but I have uploaded the whole file on Github here. I have tried to make it very simple to read with all my comments in various places of the code, please have a look, you can download the file and run it on your terminal, as long as you installed all the libraries mentioned above, there should be no problems, but if you have one, do leave a comment below or reach out to me on Twitter or Linkedin.
You can check out the final product in the below video.
Again, I would be more than happy to listen to you on some feedback and any ideas on future articles/content; I thank you for being a reader of TradeWithPython. I will soon be posting the next articles on cleaning the data downloaded and calculating adjustment factors.
If you like it up till now, consider buying me a coffee ☕ by clicking here or the button below.