

Creating Your Own Recent Stock News Sentiment Analyzer using Python
Scraping Latest GoogleNews Articles to Guage Sentiment



Have you ever thought of parsing a big news article to get its summary in seconds and running sentiment analysis on the summary of the same article? If that is the case, then you're reading the right article.📝
Also, It becomes much more fascinating when it comes to recent stock news.📈 And we're just going to do that! 😃
In this tutorial, you'll learn the impressive capabilities of the following Python packages:
Newspaper: It is a Python module used for extracting & curating articles. It extracts the important text from an article🗞 posted on a website with the help of the URL being passed.
Google News: It is used to scrape news from the Google news📰 platform.
A quick example to show you an auto-generated summary of an article using Newspaper Library
The article - IOC, BPCL, Hindustan Petroleum cut output, imports amid COVID-induced low fuel demand
Auto-Generated Summary -
India's top state oil refiners are reducing processing runs, and crude imports as the surging COVID-19 pandemic has cut fuel consumption, leading to higher product stockpiles at the plants, company officials told Reuters on Tuesday. "We do not anticipate that our crude processing would be reduced to last year's level of 65%-70% as inter-state vehicle movement is still there ... (the) economy is functioning," he said. State-run Bharat Petroleum Corp has cut its crude imports by 1 million barrels in May and will reduce purchases by 2 million barrels in June, a company official said. HPCL has no immediate plan to cut crude runs, he said, although the company has shut some units at its 150,000 bpd Mumbai refinery for maintenance and upgrade. To ease storage problems, India could export some diesel, which constitute 40% of local refiners output, another BPCL official said.
The Flow
Extract -> Summarize -> Analyze
First, We'll extract the news articles with the Google news Python package, then we'll summarize them with the Newspaper Python Package, and towards the end, we'll run sentiment analysis on the extracted & summarized news articles with the VADER.
Before starting, I am assuming that you know the nitty-gritty of Sentiment Analysis; if not, then please check out my previous article on the same.
The Python Implementation
Before we get into the main code, here is some mandatory legal text.
Disclaimer: The material in this article is purely educational and should not be taken as professional investment advice. The idea of this simple article is just to get you started and to showcase the possibilities with Python.
1. Installing the required libraries
Open the terminal and activate the conda environment to install the packages.
pip install newspaper3kpip install GoogleNewspip install nltk
2. Importing the libraries
import pandas as pd
import matplotlib.pyplot as plt
import datetime as dt
import nltk
from nltk.sentiment.vader import SentimentIntensityAnalyzer
from GoogleNews import GoogleNews
from newspaper import Article
from newspaper import Config
from wordcloud import WordCloud, STOPWORDS
nltk.download('vader_lexicon') #required for Sentiment Analysis
3. Extracting News
now = dt.date.today()
now = now.strftime('%m-%d-%Y')
yesterday = dt.date.today() - dt.timedelta(days = 1)
yesterday = yesterday.strftime('%m-%d-%Y')
nltk.download('punkt')
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:78.0) Gecko/20100101 Firefox/78.0'
config = Config()
config.browser_user_agent = user_agent
config.request_timeout = 10
Herein, We've assigned the variables to provide the timeframe of news extraction, which is essentially 1 day.
The NLTK punkt is a tokenizer (converter of data into a string of characters) that divides a text into a list of sentences by using an advanced algorithm.
We need config because sometimes newspaper package might not be able to download an article due to the restriction in accessing the article with a specified URL. To bypass that restriction, we set the user_agent variable in order to parse those restricted articles and get authorized.
At last, the connection may occasionally timeout, as it uses the Python module requests so to prevent the same, we've used config.request_timeout
Now, it's time to write the code to extract the News for a particular stock or a ticker.
# save the company name in a variable
company_name = input("Please provide the name of the Company or a Ticker: ")
#As long as the company name is valid, not empty...
if company_name != '':
print(f'Searching for and analyzing {company_name}, Please be patient, it might take a while...')
#Extract News with Google News
googlenews = GoogleNews(start=yesterday,end=now)
googlenews.search(company_name)
result = googlenews.result()
#store the results
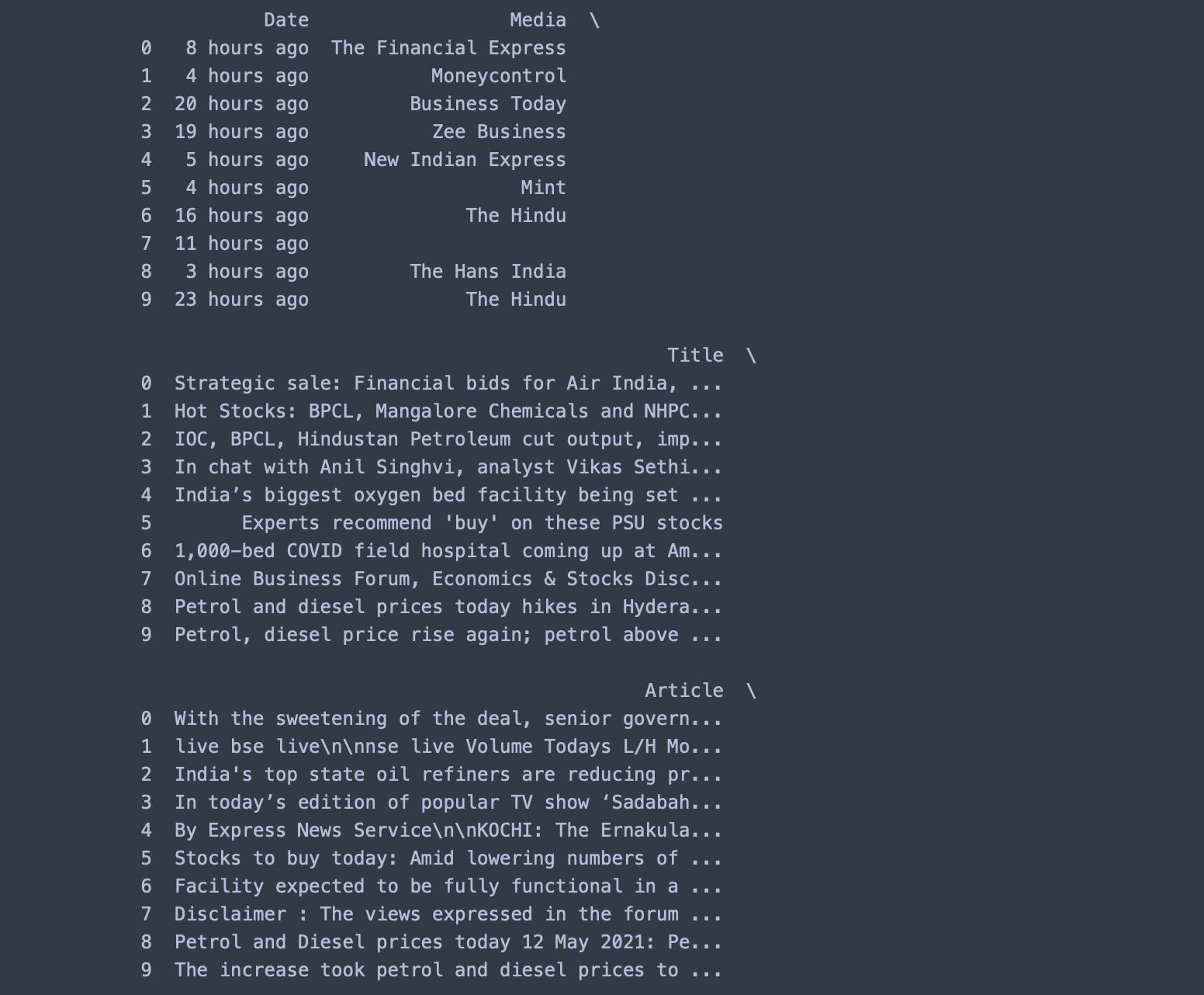
df = pd.DataFrame(result)
print(df)
Output:

It's important to note here that it fetches only 10 articles at a time that are there on the first page of the Google search; though we can fetch more articles but it'll defeat the purpose of extracting the 'Recent' News.
The above implementation uses
BPCL(Bharat Petroleum Corporation Ltd.) to extract the News over the past 1 day as an example; if you would like to see the same kind of implementation, you can open this Google Colab Notebook.
4. Summarizing
Now that we've extracted the News, we'll parse the links of extracted articles that are stored in the data frame variable and perform the NLP (Natural language processing) operations on those articles.
try:
list =[] #creating an empty list
for i in df.index:
dict = {} #creating an empty dictionary to append an article in every single iteration
article = Article(df['link'][i],config=config) #providing the link
try:
article.download() #downloading the article
article.parse() #parsing the article
article.nlp() #performing natural language processing (nlp)
except:
pass
#storing results in our empty dictionary
dict['Date']=df['date'][i]
dict['Media']=df['media'][i]
dict['Title']=article.title
dict['Article']=article.text
dict['Summary']=article.summary
dict['Key_words']=article.keywords
list.append(dict)
check_empty = not any(list)
# print(check_empty)
if check_empty == False:
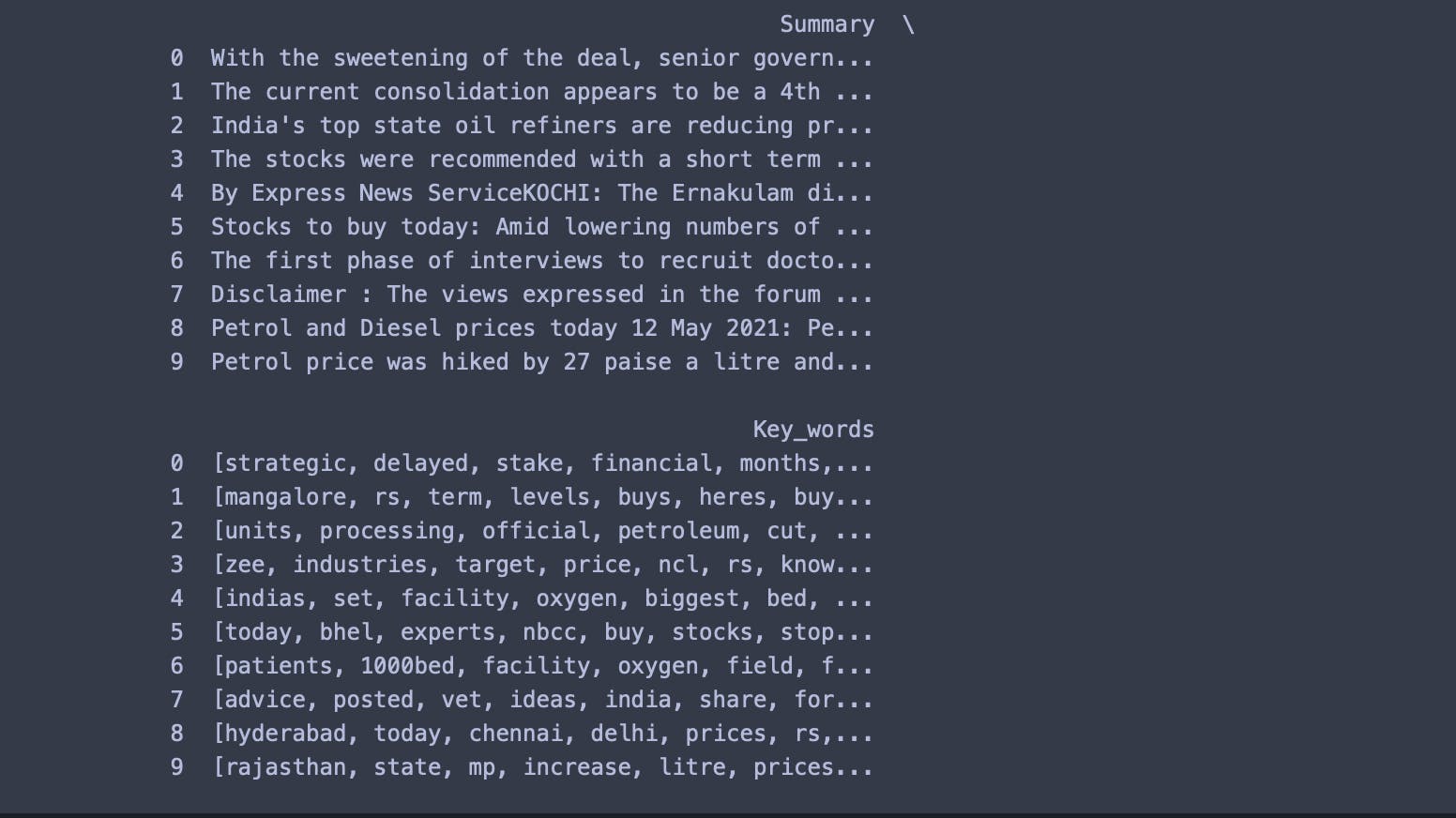
news_df=pd.DataFrame(list) #creating dataframe
print(news_df)
except Exception as e:
#exception handling
print("exception occurred:" + str(e))
print('Looks like, there is some error in retrieving the data, Please try again or try with a different ticker.' )
We've implemented Nested exception handling here because sometimes the Newspaper module throws an error related to downloading and parsing the articles, so exception handling ensures the flow of our program, and if there will be an error other than this, then our program will throw an error "upwards" instead of the error-code.
We are making sure that if the Newspaper module fails to download an article, then we'll skip the same and move on to the next article.
We're also ensuring that our list doesn't remain empty; it is because if the Newspaper module isn't able to Parse the article, then we'll not get the desired output.
Output:
5. Sentiment Analysis
This is similar to what we did in this article. If you haven't read it yet, then have a look at it.
#Sentiment Analysis
def percentage(part,whole):
return 100 * float(part)/float(whole)
#Assigning Initial Values
positive = 0
negative = 0
neutral = 0
#Creating empty lists
news_list = []
neutral_list = []
negative_list = []
positive_list = []
#Iterating over the tweets in the dataframe
for news in news_df['Summary']:
news_list.append(news)
analyzer = SentimentIntensityAnalyzer().polarity_scores(news)
neg = analyzer['neg']
neu = analyzer['neu']
pos = analyzer['pos']
comp = analyzer['compound']
if neg > pos:
negative_list.append(news) #appending the news that satisfies this condition
negative += 1 #increasing the count by 1
elif pos > neg:
positive_list.append(news) #appending the news that satisfies this condition
positive += 1 #increasing the count by 1
elif pos == neg:
neutral_list.append(news) #appending the news that satisfies this condition
neutral += 1 #increasing the count by 1
positive = percentage(positive, len(news_df)) #percentage is the function defined above
negative = percentage(negative, len(news_df))
neutral = percentage(neutral, len(news_df))
#Converting lists to pandas dataframe
news_list = pd.DataFrame(news_list)
neutral_list = pd.DataFrame(neutral_list)
negative_list = pd.DataFrame(negative_list)
positive_list = pd.DataFrame(positive_list)
#using len(length) function for counting
print("Positive Sentiment:", '%.2f' % len(positive_list), end='\n')
print("Neutral Sentiment:", '%.2f' % len(neutral_list), end='\n')
print("Negative Sentiment:", '%.2f' % len(negative_list), end='\n')
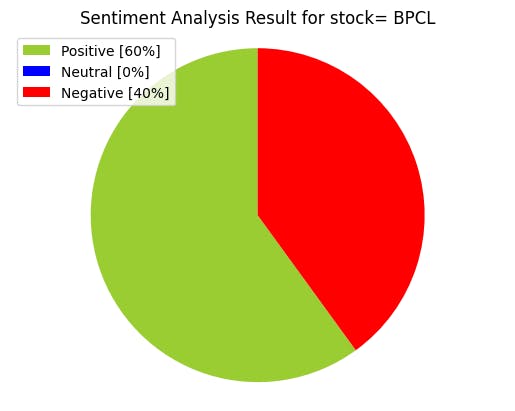
#Creating PieCart
labels = ['Positive ['+str(round(positive))+'%]' , 'Neutral ['+str(round(neutral))+'%]','Negative ['+str(round(negative))+'%]']
sizes = [positive, neutral, negative]
colors = ['yellowgreen', 'blue','red']
patches, texts = plt.pie(sizes,colors=colors, startangle=90)
plt.style.use('default')
plt.legend(labels)
plt.title("Sentiment Analysis Result for stock= "+company_name+"" )
plt.axis('equal')
plt.show()
# Word cloud visualization
def word_cloud(text):
stopwords = set(STOPWORDS)
allWords = ' '.join([nws for nws in text])
wordCloud = WordCloud(background_color='black',width = 1600, height = 800,stopwords = stopwords,min_font_size = 20,max_font_size=150,colormap='prism').generate(allWords)
fig, ax = plt.subplots(figsize=(20,10), facecolor='k')
plt.imshow(wordCloud)
ax.axis("off")
fig.tight_layout(pad=0)
plt.show()
print('Wordcloud for ' + company_name)
word_cloud(news_df['Summary'].values)
Output:

6. Wrapping it up
And with that, it's a wrap! I hope you found the article useful!
You can also access the GitHub link here to view the entire code in one single file directly.
Thank you for reading; if you have reached so far, please like the article; it will encourage me to write more such articles. Do share your valuable suggestions; I would really appreciate your honest feedback!🙂
Please feel free to leave a comment and connect if you have any questions regarding this or require any further information. Consider subscribing to my mailing list for automatic updates on future articles. 📬
I would love to connect with you over Mail, or you can also find me on Linkedin
If you liked this article, consider buying me a book 📖 by clicking here or the button below.